大模型学习全攻略 从零基础到AI专家的系统性路线图
引言:拥抱AI时代
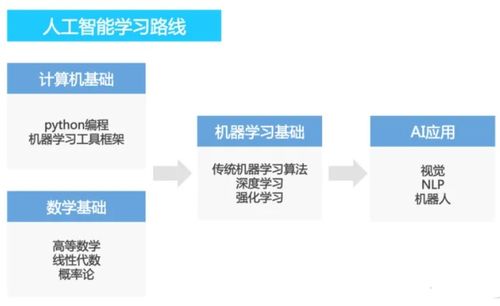
随着以ChatGPT、文心一言等为代表的大模型技术席卷全球,掌握大模型开发与应用能力已成为个人职业发展和技术创新的关键。本路线图旨在为零基础新手、在校大学生以及有志于转型的技术开发者,提供一条清晰、系统、循序渐进的学习路径,助你从AI小白稳步成长为AI领域的专家。
第一阶段:基础筑基(1-3个月)
目标: 构建坚实的数理与编程基础,理解AI核心概念。
- 数学基础:
- 线性代数: 重点掌握向量、矩阵、张量运算及其几何意义,这是理解神经网络数据流动的基石。
- 概率论与数理统计: 理解概率分布、贝叶斯定理、期望与方差,为学习模型的不确定性评估和生成模型打基础。
- 微积分: 重点理解导数和梯度,这是深度学习模型训练(反向传播)的核心数学工具。
- 编程与工具:
- Python编程: 熟练掌握Python语法、数据结构、函数、面向对象编程及常用库(如NumPy, Pandas)。Python是AI领域的绝对主流语言。
- 开发环境: 熟悉Jupyter Notebook、PyCharm/VSCode等IDE,学会使用Git进行版本控制和代码托管(GitHub/Gitee)。
- 机器学习入门:
- 经典算法: 理解线性回归、逻辑回归、决策树、支持向量机(SVM)等监督学习算法的原理与应用场景。
- 核心概念: 透彻理解过拟合/欠拟合、偏差与方差、交叉验证、特征工程、模型评估指标(准确率、精确率、召回率等)。
- 推荐学习: 吴恩达《机器学习》课程(Coursera),或李航《统计学习方法》书籍。
第二阶段:深度学习进阶(2-4个月)
目标: 掌握深度学习的核心架构与训练技巧,为理解大模型铺路。
- 神经网络基础:
- 前向传播与反向传播: 深入理解神经网络的训练机制。
- 激活函数、损失函数与优化器: 掌握Sigmoid、ReLU、Softmax等函数,以及SGD、Adam等优化算法的原理。
- 主流网络架构:
- 卷积神经网络(CNN): 掌握其结构(卷积层、池化层)及其在计算机视觉(CV)中的应用(如图像分类)。
- 循环神经网络(RNN)与长短时记忆网络(LSTM): 理解其处理序列数据(如文本、时间序列)的能力,是理解Transformer前的重要一步。
- 深度学习框架:
- PyTorch 或 TensorFlow: 任选其一深入学习和实践。目前学术界和工业界(尤其在大模型领域)更倾向于PyTorch。务必动手完成从模型搭建、训练、评估到部署的全流程项目。
第三阶段:大模型核心技术(3-6个月)
目标: 深入理解大模型的基石——Transformer架构及其演进。
- Transformer架构精讲:
- 核心组件: 彻底搞懂自注意力机制(Self-Attention)、多头注意力(Multi-Head Attention)、位置编码(Positional Encoding)、前馈网络(FFN)的原理与实现。
- 编码器-解码器结构: 理解其在机器翻译等序列到序列任务中的工作流程。
- 必读论文: 《Attention Is All You Need》。
- 预训练语言模型演进:
- 从BERT到GPT: 对比学习BERT(双向编码器,擅长理解)和GPT系列(自回归解码器,擅长生成)的预训练目标(掩码语言建模MLM vs 下一词预测)、架构差异与应用场景。
- 大模型关键技术: 理解规模化(Scaling Laws)、提示工程(Prompt Engineering)、指令微调(Instruction Tuning)、基于人类反馈的强化学习(RLHF)等让大模型“智能”涌现的关键技术。
- 实践与探索:
- 使用Hugging Face: 熟练使用Hugging Face的
transformers、datasets、accelerate等库,加载预训练模型、进行微调、部署推理。
- 动手微调模型: 在公开数据集上,尝试对BERT或较小的开源大模型(如ChatGLM-6B、Qwen-7B、Llama 2-7B)进行领域适配微调或指令微调。
第四阶段:深入专业与前沿(持续学习)
目标: 根据兴趣选择细分方向深耕,跟踪前沿技术。
- 专业方向选择:
- 大模型开发与训练: 深入研究分布式训练、混合精度训练、模型并行、数据并行等大规模训练技术,了解Megatron-LM、DeepSpeed等框架。
- 大模型应用与部署: 学习模型压缩(量化、剪枝、知识蒸馏)、服务化框架(如vLLM、TGI)、边缘部署、AI Agent智能体构建等。
- 多模态大模型: 学习CLIP、Stable Diffusion、GPT-4V等多模态模型的原理,探索图文生成、视觉问答等应用。
- 领域大模型: 深入金融、医疗、法律、代码等垂直领域,研究如何利用领域数据与知识构建和优化专业模型。
- 前沿跟踪与社区参与:
- 关注顶会与论文: 定期阅读NeurIPS、ICLR、ACL、CVPR等顶级会议的最新论文。
- 参与开源项目: 在GitHub上阅读优秀开源大模型项目代码,尝试提交Issue或PR,是快速提升的捷径。
- 构建作品集: 通过个人博客、GitHub、技术社区分享你的学习心得、项目经验和实验成果,打造个人品牌。
学习建议与资源
- 保持动手: “纸上得来终觉浅,绝知此事要躬行。” 每个阶段都要辅以足够的代码实践和项目练习。
- 由浅入深: 不要一开始就扎进大模型论文的复杂公式,务必打好数学和深度学习基础。
- 善用资源:
- 在线课程: 李沐《动手学深度学习》、斯坦福CS224N(NLP)、CS231N(CV)。
- 书籍: 《深度学习》(花书)、《神经网络与深度学习》(邱锡鹏)、《自然语言处理:基于预训练模型的方法》。
- 社区: Hugging Face、Papers With Code、知乎、AI技术博客。
##
学习大模型是一场充满挑战与机遇的马拉松。这条路线图为你规划了清晰的阶段和路径,但最重要的是保持持续的热情、好奇心和强大的执行力。从今天开始,迈出第一步,逐步构建你的AI知识体系与技能树,未来已来,你正身处其中。
如若转载,请注明出处:http://www.vcazx.com/product/44.html
更新时间:2026-06-19 00:17:09